
解説と解答
ここでは、次の問題の表題や本文の赤字の語句が解答例になっています。
つまり、問題 1-1 の答えは「核」 、 1-2 は「染色体」、1-3 は「DNA」、1-4 は「ヌクレオチド」です。
DNAは長い鎖状の分子です。下の図にはヌクレオチド(nucleotide)が4つだけ連なった形で書いてい ますが、実際のゲノムでは数十万から数千万も連なっています。図の上が5'末端、下が3'末端とよばれます。
図 DNA1本鎖の化学構造
下 の図にあるように、ヌクレオチドはリン酸基と糖と塩基の3部分からなっています。DNAを構成するヌクレオチドでは、糖は2'-デオキシリボース(2'-deoxyribose)です。"DNA"の"D"は、この「デオキシ」からきています。下の図では塩基としてアデニン(Aと略される)を例示しています。

図 ヌクレオチド
この図に例示したヌクレオチドはリン酸基が3つ結合しており、全体で2'-デオキシアデノシン三リン酸(2'-deoxyadenosine 5'-triphosphate、略してdATP)と呼ばれます。
ヌクレオチドが重合してできたDNAの中では、上の「解説と解答 1-4」の図にあったように、リン酸基が1つづつになります。DNAではリン酸基と糖がDNAの背骨を作り、塩基(図ではG, C, T, Aの部分)が横に張り出しています。
下の図に示すように(また1-4の図にもあったように)、A、T、G、Cの4種があります。これらの記号はそれぞれアデニン、チミン、グアニン、シトシンという塩基性 複素環式化合物の名称の頭文字です。

図 4種類の塩基と塩基対
下の図に模式的に示したように、DNA分子は2本が寄り添ってらせんを巻いています。2本は塩基の部分で結合しており、AはTと、GはCと、それぞれ対になります。これを塩基対(base pair、略してbp)といいます。bpはDNAの長さの単位にもなります。たとえば「ひとのゲノムは約 3 x 10 9 bpである」というように。前問の「解説と解答」の図にあるように、AとTは2本の水素結合で、GとCは3本の水素結合で結ばれています。

図 DNAの二重らせん構造
塩基対の組み合わせはこのように厳格に決まっているので、片方の鎖の塩基配列がわかれば他方の鎖の塩基配列も自動的にわかります。このように、対合する2本の核酸の配列が厳密に対応することを相補的(complementary)であるといいます。
DNA鎖の2つの末端は、「解説と解答 1-4 」にもあったように、5'末端と3'末端とよんで区別されます。2本鎖DNAは、互いに逆方向です。
複製(duplication)とよばれます。この反応は下の図に示すように、DNA依存性DNAポリメラ-ゼ(重合酵素)が触媒します。

図 DNAのはたらきのまとめ
なおこの図には、DNAのはたらきとして複製のほかに発現の過程も示していますが、そちらについては次の問題を見てください。
転写 (transcription)と翻訳 (translation)といいます。DNAのはたらきをまとめた下のような模式図を「セントラルドグマ」といいます。
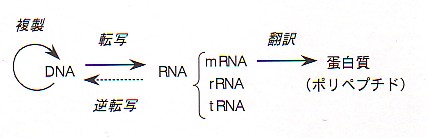
図 分子生物学のセントラルドグマ
RNAの4つの塩基はA、U、G、Cです。DNAのTの代わりにUが使われています。その点を除けば、DNAの複製のときと同様に配列の相補的な鎖が合成されます。
タンパク質の基本構造であるポリペプチドは、主に20種類のアミノ酸が厳密かつ複雑な配列で重合してできています。このアミノ酸の一次元的な配列をmRNAの塩基配列が決めています。

図 20種類のアミノ酸
この図では左上にアミノ酸の基本構造を示しています。このうちの「R」で表示した基が20種類あります。そのR基のみを図に示しています。

カバ
第2章 演習;配列解析の初歩
AにはT、TにはA、GにはC、CにはGを当てはめていけばいいわけです。末端の方向を明示する習慣をつけましょう。
5' ... AGCCG TCGTC AAGCA CAACC ... 3'
3' ... TCGGC AGCAG TTCGT GTTGG ... 5'
開始メチオニンのコドンATGのある鎖と同じ側の配列が、ただRNAですからTがUに置き換わります。
開始Met
5'...CCCGC AGACC CCAGA GGAAA ATAGC ATGGC TA...3'
3'...GGGCG TCTGG GGTCT CCTTT TATCG TACCG AT...5'
5'...CCCGC AGACC CCAGA GGAAA AUAGC AUGGC UA...3'
転写は開始メチオニンのAUGから始まるのではなく、その少し上流から始まります。mRNAはAUGより上流のリボソーム結合部位(ribosome binding sequence, rbs)でリボソームに結合する必要があるからです。
tRNAのアンチコドンはmRNAのコドンに相補的です。方向を表わす"3'"や"5'"の方向に注意しましょう。tRNAに結合するアミノ酸残基はmRNAのコドンを参照してコドン表で求めます。
アンチコドン アミノ酸残基
3' 5'
2番目 CUA アスパラギン酸(Asp)
3番目 UUU フェニルアラニン(Phe)
DNA断片の配列が与えられると、その鎖に1塩基ずつずらした3つの読み枠を取ることができる(図の下段3行)。また、その相補鎖にも3つの読み枠がある(図の上段3行) ので,計6つである。ただし後者は方向が逆(右から左の向き)であることに注意 。

図 6つの読み枠
下の図に赤の矢印で示すように、順方向に3つの長いORFが認められます。それらのアミノ酸配列でタンパク質のデータベースを検索し、既知のタンパク質と配列が似ていれば、有力な遺伝子候補で す。タンパク質のアミノ酸配列を実験的に決めてそれと一致すれば、実際の遺伝子であることが証明できたことになります。

図 ORF解析の解答例。
細菌のゲノムには遺伝子が密に詰まっています。特に、オペロンとよばれる遺伝子群の中では、遺伝子間の隙間は狭く、逆に数残基重なっている場合もあります。
A) 25残基目からc) のCuA結合部位を含む。このことは、このタンパク質がシトクロムc酸化酵素のサブユニットIIであることを示している。
B) 11残基目からb) のヘム-銅酸化酵素の活性中心のモチーフを含む。このことは、このタンパク質が呼吸鎖末端酸化酵素のサブユニットIであることを示してる。
C) 7残基目と117残基目からc) のヘムC結合部位を含む。このことは、このタンパク質が(少なくとも)ジヘムのc型シトクロムであることを示している。
ここにはシトクロム関係のモチーフを例示しましたが、さまざまな種類のタンパク質でこのような配列モチーフが明らかになっています。
a) ヘムC結合部位が1つ目の遺伝子qcrC に2つあります。図の中で波下線をつけています。
なお、問題の図は遺伝子配列の実例ですからよく見てください。細菌のゲノムのオペロン内では、このようにとなり合った遺伝子が数bpながら塩基配列を重複して利用していることがあります。細菌や古細菌の遺伝子は多くの場合qcrAとかcoxB などのように小文字3文字と大文字1文字の組み合わせで名づけられ、斜体で表わされます。それらの遺伝子産物(つまりタンパク質やポリペプチド)は、QcrAとかCoxBのように1文字目を大文字に変え立体で表わします。
問題の図を簡潔な模式図に表わしたのが下の図です。遺伝子1づつを横長の5角形(矢印)で表わすことがよくあります。矢の向きが転写の方向です。次の章で見るように、ゲノム全体を模式的に表わせばこのような矢印が数百から数万ならぶことになります。

図 qcrCAB 遺伝子クラスターの模式図
3つの遺伝子はそれぞれシトクロムcc 、鉄-イオウタンパク質、シトクロムb をコードする。新しく発見したこのシトクロムcc は、ヘムCを2つ結合しており、アミノ酸配列上はCXXCHモチーフが2つある(短い縦棒で表示)。

ボタン
第3章 ゲノムの全体像
マイコプラズマ菌のゲノムには470個の遺伝子があります。ゲノムのサイズ58万70 bpを470で割ると、約1200となります。この値は原核生物ではほぼ共通で、1000~1200程度です。この数値には、短いとはいえ遺伝子間のDNA鎖も含まれています。遺伝子ではない部分を除き、また3 bpで1アミノ酸残基を指定することを考えると、遺伝子産物は平均約300のアミノ酸残基を含むことになります。
真核生物でも遺伝子産物のサイズはあまり大きくは違いません。しかし遺伝子間のDNA鎖やイントロンがあるため、1遺伝子あたりのゲノム塩基対の数は原核生物の場合より大きくなります。酵母では約2000 bpですが、ヒトでは約10万 bpにもなります。
4100個の遺伝子のうち4割以上が機能不明(表の中のV群 + VI群)であることがまず注目されます。枯草菌に限らずたいていの生物のゲノムでは、機能不明の遺伝子の割合がこのように高くなっています。
機能が分かっている遺伝子の中では、代謝(II群)と情報経路(III群)のまとまりが目立ちます。この代謝とは、細胞内での物質の変化の個とであり、代謝にかかわる遺伝子の産物とは、その変化を触媒する酵素です。解糖系(II.1.2)とクエン酸回路(II.1.3)が代謝の中核になっています。アミノ酸は20種類もあるので、それの分解と生合成をつかさどる酵素(II.2)は多数に上っていますが、ヌクレオチドと核酸にかかわる酵素(II.3)も重要です。なお、生命体の有機化合物を構成する6大元素のうち、C, H, O, Nに比べるとPとSの含量も少なめなため、燐酸の代謝(II.6)とイオウの代謝(II.7)にかかわる遺伝子も少なめですが、やはり重要です。
この表でいう情報経路とは、遺伝情報の複製と発現のことです。複製(III.1)、転写(III.5)、翻訳(III.7)の3つの基本過程のほかにも、表に示すような機能について多くの遺伝子がはたらいています。
膜タンパク質のうち、脂質二重膜に埋め込まれたものを内在性タンパク質(integral membrane protein)とよぶのに対し、膜の表面に結合したものを表在性膜タンパク質(peripheral membrane protein)といいます。
細胞骨格には、アクチンからなる微小繊維のほかに、チューブリンからなる微小管も重要です。動物では第3の細胞骨格として中間系フィラメントもあります。
核酸はDNAとRNAに分けられます。DNA結合タンパク質ほどではありませんが、RNA結合タンパク質も少なくありません。
1) DNA複製や転写・翻訳、タンパク質修飾など、遺伝情報の伝達と発現にかかわる遺伝子は、どの生物のゲノムにもほぼ同様に大きな割合で含まれているようです。輸送にかかわる膜タンパク質も共通に多いのは、細胞の内側を外界から隔絶された特定の条件に保つことが、やはりどの生物にも必要だからでしょう。
2) 代謝にかかわる遺伝子は植物にきわだって多く、菌類がそれに次いでいます。解糖系やクエン酸回路など中心的な代謝経路はどの生物にも共通ですが、動くことのできない植物は、栄養の獲得や防御もすべて自前の遺伝子で合成する物質に頼っているようです。植物は抗がん剤など新規な有用物質の宝庫と目されており、環境破壊や農業の「モノカルチャー化」に対抗して守るべき遺伝子資源としても、植物が大きな割合を占めています。
3) リン酸化酵素やセカンド=メッセンジャーなど細胞内での信号伝達にかかわる遺伝子はどの生物でも多い。これと対照的に、ホルモンや神経伝達物質など細胞間の信号伝達にかかわる遺伝子は、線虫やヒトなどの動物では細胞内信号伝達遺伝子に匹敵するくらい多いのに対して、酵母や植物ではわずかです。動物のうちでもショウジョウバエでは少なめになっています。酵母は単細胞生物だから多細胞生物よりずっと少ないのはもっともです。多細胞生物のうちでも、植物は身体の各部分の独立性が高いのに対し、動物の身体は各部分が密に連携してはたらいていることを反映していると見られます。
4) 上記2)や3)で述べたこともこれに該当します。その他では、細胞骨格等が動物では共通に多めです。植物は多糖類でできた細胞壁がおもに細胞を支えているのに対し、動物では細胞骨格や細胞外の構造タンパク質が細胞を支えています。さらに、運動もミオシンやダイニンなど細胞骨格と相互作用するタンパク質が担っていることも、この割合に寄与しているでしょう。
5) 抗体など免疫にかかわる遺伝子の多いのが目立ちます。動物のうちでも身体の体制が複雑化し、寿命(あるいは誕生から繁殖期までの期間)がながくなった脊椎動物は、生体防御のしくみも精密化する必要があったわけです。ほかに、多機能タンパク質も多くなっています。

キノコ
第4章 分子進化と遺伝子工学
ヒト(human)とウシ(bovine)では4つのアミノ酸が違っています。ヒトとシチメンチョウ(turkey)では5つ、ある種の小型サメ(dogfish)とでは8つ違います。酵母(yeast)とではどうでしょうか。ほとんど軒なみ違っていて、50個中48個も違っている...でしょうか?よく見ると酵母のシトクロムc の配列を左に1つずれせば、かなり一致してきます。違いは17個となりますね。このように配列を比較する場合、機械的にN末端から比べたのでは無意味になるが、適当にずらすことによって偶然ではないほど一致する場合がよくあります。ただし恣意的にずらして無理やり合わせるのも不適切です。
アミノ酸配列の違いが、哺乳類どうしでは少なく、哺乳類と鳥類では少し多くなっています。また恒温動物どうしより、恒温動物と変温動物ではより多くなり、動物と菌類ではさらに多くなっています。やはりこのように、生物の系統関係が近いほどタンパク質のアミノ酸配列も近いことがわかります。
これらの酸化酵素はまずアミノ酸配列のみならずサブユニット構成なども異なる2つのグループ(M型とB型)に分かれます。M型の酵素では、基質の違う4つのタイプが認められます。この4つは、分子進化の系統アミノ酸配列の類似度の上である程度のまとまりはありますが、系統の離れた生物にまたがる場合もあります。また、同一の生物のゲノムに複数の酸化酵素を持つ例も多い(好熱性バシラスやテルモフィルス菌など)。
コドン表を第2章の場合と逆にたどることによって、下のように推定することができます。
1 5 10 15
アミノ酸配列 M S T I A R K K G H V G P L F . . .
1 5 10 15 20 25 30 35 40
塩基配列 5' ATGTCTACTATTGCTCGTAAAAAAGGTCATGTTGGTCCTTTTTTT 3'
AGC C C CA C G G C C C C CC C C
A A A A A A A A A A
G G G G G G G G G
多くのアミノ酸は複数のコドンに対応するので、塩基配列の多くの位置は、塩基を1種類にしぼることはできません。たとえば、7位は"A"に決まりますが、9位はT, C, A, Gのいずれであるかは分かりませんし、16位はCかAのどちらか決められません。ただし同じアミノ酸でも、生物によって頻繁に使われるコドンとあまり使われないコドンがあります。これをコドン利用率(codon usage)といいます。まったく使われないコドンがあれば、その塩基は除外して考えることができます。
連続した17残基で塩基の組み合わせの数が最小になるように範囲を選ぶわけです。すると19残基目のAから35残基目のGまでの範囲がよいと分かります。この範囲で21残基目と24,30残基目が2種類の塩基、27残基目と33残基目が4種類の塩基の混合物にしなければなりません。結局 23 x 42 = 128 通りの組み合わせになります。すなわち、合成オリゴヌクレオチドのうち128分の1だけが真の遺伝子に適合する配列になるわけです。
混合塩基を1文字で表現すると、
1 5 10 15
5' AARAARGGNCAYGTNGG 3'
となります。
お疲れさまでした。